
Trying out new Unity API: BatchRendererGroup
The goal of this post is to look at the new BatchRendererGroup API (BRG) and implement the minimal BRG example, so it is easier to understand how to work with it. Then gradually add more complex functionality. In the end, we would have this boids simulation rendered using BRG:

In this post we will do the following examples and then perform some profiling to compare how usable is it:
For impatient: you can take all the samples including boids at GitHub: Unity-BatchRendererGroup-Boids
1. Simple Example
As a starting point, we can use the example provided by Unity Technologies. Firstly, I decided to strip it down to the bare minimum in order to better control and debug how everything is stored in the memory so BRG API can process it. So I removed the custom struct PackedMatrix from Unity’s sample, as well as color to simplify the data buffer, here you can check the diff how I simplified it. Also, you can copy-paste the entire file from the gist SimpleBRGExample.cs.
Unity’s example uses PackedMatrix to pack data, I used float3x4 to represent data in my example. An important point to know is how BRG expects data to be sequenced. PackedMatrix as well as float3x4 stores data in the following order (“c” means column):
// float3x4 is stored by columns
float3x4(
c0.x, c0.y, c0.z, c1.x,
c1.y, c1.z, c2.x, c2.y,
c2.z, c3.x, c3.y, c3.z
);
// While Matrix4x4 is stored by rows
Matrix4x4(
c0.x, c1.x, c2.x, c3.x,
c0.y, c1.y, c2.y, c3.y,
c0.z, c1.z, c2.z, c3.z,
c0.w, c1.w, c2.w, c3.w,
);
// So Matrix4x4.identity that stored in memory like this
Matrix4x4(
1, 0, 0, 0
0, 1, 0, 0
0, 0, 1, 0
0, 0, 0, 1
);
// should be packed into float3x4 like this to be suitable for BRG
float3x4(
1, 0, 0, 0,
1, 0, 0, 0,
1, 0, 0, 0
);
// And if we would like to translate any Vector3 position = (x, y, z)
float3x4(
1, 0, 0, 0,
1, 0, 0, 0,
1, x, y, z
);
Another important thing to know is how to calculate GPU addresses of our arrays inside GraphicsBuffer.
The first 64 bytes are zeroes, so loads from address 0 return zeroes. This is a BatchRendererGroup convention.
Then 32 uninitialized bytes to make working with GraphicsBuffer.SetData easier, otherwise unnecessary. In the boids example we will get back to this and see that we can write data right at address 64, omitting uninitialized area.
After that, there is the first array float3x4[] _objectToWorld, since there is only one instance in this array then its size is (sizeof(float) * 3 * 4) = 48 bytes.
And another float3x4[] _worldToObject in the end.
So each array goes one after another. If we had to render 2 meshes, then the size of _objectToWorld will be 48 * 2, therefore GPU address of _worldToObject would be offset further by additional 48 bytes for each additional instance.
These addresses are used to SetData and for MetadataValue.
// In this simple example, the instance data is placed into the buffer like this:
// Offset | Description
// 0 | 64 bytes of zeroes, so loads from address 0 return zeroes
// 64 | 32 uninitialized bytes to make working with SetData easier, otherwise unnecessary
// 96 | unity_ObjectToWorld, array with one float3x4 matrix
// 144 | unity_WorldToObject, array with one float3x4 matrix
// Compute start addresses for the different instanced properties. unity_ObjectToWorld starts
// at address 96 instead of 64, because the computeBufferStartIndex parameter of SetData
// is expressed as source array elements, so it is easier to work in multiples of sizeof(PackedMatrix).
const uint byteAddressObjectToWorld = SizeOfPackedMatrix * 2;
const uint byteAddressWorldToObject = byteAddressObjectToWorld + SizeOfPackedMatrix * InstanceCount;
// Upload our instance data to the GraphicsBuffer, from where the shader can load them.
_instanceData.SetData(zero, 0, 0, 1);
_instanceData.SetData(objectToWorld, 0, (int) (byteAddressObjectToWorld / SizeOfPackedMatrix), objectToWorld.Length);
_instanceData.SetData(worldToObject, 0, (int) (byteAddressWorldToObject / SizeOfPackedMatrix), worldToObject.Length);
// Set up metadata values to point to the instance data. Set the most significant bit 0x80000000 in each,
// which instructs the shader that the data is an array with one value per instance, indexed by the instance index.
// Any metadata values used by the shader and not set here will be zero. When such a value is used with
// UNITY_ACCESS_DOTS_INSTANCED_PROP (i.e. without a default), the shader will interpret the
// 0x00000000 metadata value so that the value will be loaded from the start of the buffer, which is
// where we uploaded the matrix "zero" to, so such loads are guaranteed to return zero, which is a reasonable
// default value.
var metadata = new NativeArray<MetadataValue>(2, Allocator.Temp)
{
[0] = new MetadataValue
{
NameID = Shader.PropertyToID("unity_ObjectToWorld"),
Value = 0x80000000 | byteAddressObjectToWorld,
},
[1] = new MetadataValue
{
NameID = Shader.PropertyToID("unity_WorldToObject"),
Value = 0x80000000 | byteAddressWorldToObject,
}
};
Calculated addresses are divided by the size of a 3×4 matrix. I think it is done that way because if decompiled inside SetData we can see that they use Marshal.SizeOf(data.GetType().GetElementType()), which is used in the external call to multiply the passed address and then used as an offset in GraphicsBuffer. So that’s why we need to divide it on our side.
[SecuritySafeCritical]
public void SetData(
Array data,
int managedBufferStartIndex,
int graphicsBufferStartIndex,
int count)
{
if (data == null)
throw new ArgumentNullException(nameof (data));
if (!UnsafeUtility.IsArrayBlittable(data))
throw new ArgumentException(string.Format("Array passed to GraphicsBuffer.SetData(array) must be blittable.n{0}", (object) UnsafeUtility.GetReasonForArrayNonBlittable(data)));
if (managedBufferStartIndex > 0 || graphicsBufferStartIndex > 0 || count > 0 || managedBufferStartIndex + count < data.Length)
throw new ArgumentOutOfRangeException(string.Format("Bad indices/count arguments (managedBufferStartIndex:{0} graphicsBufferStartIndex:{1} count:{2})", (object) managedBufferStartIndex, (object) graphicsBufferStartIndex, (object) count));
this.InternalSetData(data, managedBufferStartIndex, graphicsBufferStartIndex, count, Marshal.SizeOf(data.GetType().GetElementType()));
}
So these 2 matrices are the minimum data needed to render a mesh properly.
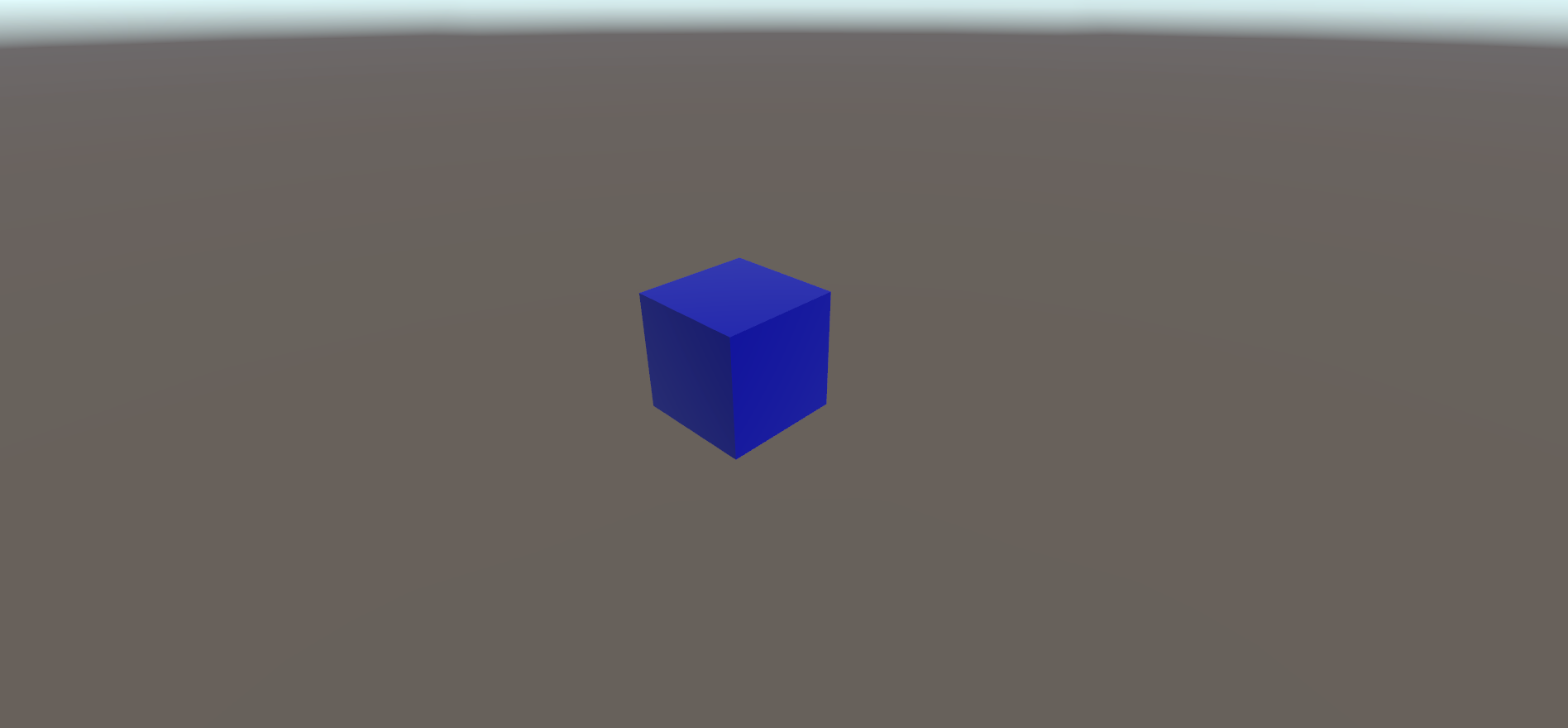
Without inverse matrix, the mesh would be rendered, but without any color or lighting applied.

Apart from these points, there are not so many changes to Unity’s example. OnPerformCulling is grabbed completely unchanged. Again you can grab the source code to play around with the minimal sample here: SimpleBRGExample.cs
2. Simple Movement
Now let’s add movement to the rendered mesh. We need some more serialized fields to control the movement via the inspector:
// Add new serialize fields to control the movement via inspector [SerializeField] private float _motionSpeed; [SerializeField] private float _motionAmplitude; [SerializeField] private Vector3 _position; [SerializeField] private Vector3 _motionDirection; // Helper field to calculate position using cosine function private float _phase; // Save matrices and gpu addresses into fields to use it in the Update() method private float3x4[] _objectToWorld; private float3x4[] _worldToObject; private uint _byteAddressWorldToObject; private uint _byteAddressObjectToWorld;
And recalculate the position every frame using the cosine function and adding it to the current position to create a simple wobbly movement with the mesh. Then just call _instanceData.SetData to update the data in GraphicsBuffer with arrays containing the new position and it’s inverse the same way as in the Start():
private void Update()
{
_phase += Time.fixedDeltaTime * _motionSpeed;
var translation = _motionDirection * _motionAmplitude;
var pos = translation * Mathf.Cos(_phase);
UpdatePositions(pos);
}
private void UpdatePositions(Vector3 pos)
{
_objectToWorld[0] = new float3x4(
new float3(_objectToWorld[0].c0.x, _objectToWorld[0].c0.y, _objectToWorld[0].c0.z),
new float3(_objectToWorld[0].c1.x, _objectToWorld[0].c1.y, _objectToWorld[0].c1.z),
new float3(_objectToWorld[0].c2.x, _objectToWorld[0].c2.y, _objectToWorld[0].c2.z),
new float3(_objectToWorld[0].c3.x + pos.x, _objectToWorld[0].c3.y + pos.y, _objectToWorld[0].c3.z + pos.z)
);
_worldToObject[0] = new float3x4(
new float3(_worldToObject[0].c0.x, _worldToObject[0].c0.y, _worldToObject[0].c0.z),
new float3(_worldToObject[0].c1.x, _worldToObject[0].c1.y, _worldToObject[0].c1.z),
new float3(_worldToObject[0].c2.x, _worldToObject[0].c2.y, _worldToObject[0].c2.z),
new float3(_worldToObject[0].c3.x - pos.x, _worldToObject[0].c3.y - pos.y, _worldToObject[0].c3.z - pos.z)
);
_instanceData.SetData(_objectToWorld, 0, (int) (_byteAddressObjectToWorld/ SizeOfPackedMatrix) ,_objectToWorld.Length);
_instanceData.SetData(_worldToObject, 0, (int) (_byteAddressWorldToObject / SizeOfPackedMatrix), _worldToObject.Length);
}
3. Multiple objects
Let’s further increase the example’s complexity and render more than one object on the screen. Add a new serialized field to control the amount of objects and update initialization to generate that amount of matrices, as well as calculate correctly the address of the _worldToObject array with a new offset based on the amount of matrices inside _objectToWorld array:
[SerializeField] private uint _instancesCount = 1;
...
private void Start()
{
var bufferCountForInstances = BufferCountForInstances(BytesPerInstance, (int) _instancesCount, ExtraBytes);
...
var matrices = new float4x4[_instancesCount];
for (var i = 0; i < matrices.Length; i++)
{
matrices[i] = Matrix4x4.Translate(_position * i);
}
// Convert the transform matrices into the packed format expected by the shader
_objectToWorld = new float3x4[_instancesCount];
for (var i = 0; i < _objectToWorld.Length; i++)
{
_objectToWorld[i] = new float3x4(
matrices[i].c0.x, matrices[i].c1.x, matrices[i].c2.x, matrices[i].c3.x,
matrices[i].c0.y, matrices[i].c1.y, matrices[i].c2.y, matrices[i].c3.y,
matrices[i].c0.z, matrices[i].c1.z, matrices[i].c2.z, matrices[i].c3.z
);
}
// Also create packed inverse matrices
var inverse = math.inverse(matrices[0]);
_worldToObject = new float3x4[_instancesCount];
for (var i = 0; i < _worldToObject.Length; i++)
{
_worldToObject[i] = new float3x4(
inverse.c0.x, inverse.c1.x, inverse.c2.x, inverse.c3.x,
inverse.c0.y, inverse.c1.y, inverse.c2.y, inverse.c3.y,
inverse.c0.z, inverse.c1.z, inverse.c2.z, inverse.c3.z
);
}
// Calculate arrays' GPU addresses using _instanceCount
_byteAddressObjectToWorld = SizeOfPackedMatrix * 2;
_byteAddressWorldToObject = _byteAddressObjectToWorld + SizeOfPackedMatrix * _instancesCount;
...
}
...
And of course, we need to adjust UpdatePositions method to use an indexer instead of 0:
private void UpdatePositions(Vector3 pos)
{
for (var i = 0; i < _instancesCount; i++)
{
_objectToWorld[i] = new float3x4(
new float3(_objectToWorld[i].c0.x, _objectToWorld[i].c0.y, _objectToWorld[i].c0.z),
new float3(_objectToWorld[i].c1.x, _objectToWorld[i].c1.y, _objectToWorld[i].c1.z),
new float3(_objectToWorld[i].c2.x, _objectToWorld[i].c2.y, _objectToWorld[i].c2.z),
new float3(_objectToWorld[i].c3.x + pos.x, _objectToWorld[i].c3.y + pos.y, _objectToWorld[i].c3.z + pos.z));
_worldToObject[i] = new float3x4(
new float3(_worldToObject[i].c0.x, _worldToObject[i].c0.y, _worldToObject[i].c0.z),
new float3(_worldToObject[i].c1.x, _worldToObject[i].c1.y, _worldToObject[i].c1.z),
new float3(_worldToObject[i].c2.x, _worldToObject[i].c2.y, _worldToObject[i].c2.z),
new float3(_worldToObject[i].c3.x - pos.x, _worldToObject[i].c3.y - pos.y, _worldToObject[i].c3.z - pos.z));
}
_instanceData.SetData(_objectToWorld, 0, (int) (_byteAddressObjectToWorld / SizeOfPackedMatrix), _objectToWorld.Length);
_instanceData.SetData(_worldToObject, 0, (int) (_byteAddressWorldToObject / SizeOfPackedMatrix), _worldToObject.Length);
}
Let’s also modify spawn positions, so we can actually see a big amount of meshes on the screen at the same time by using a handy Random.onUnitSphere property and a _radius field. This will give us all meshes being uniformly spread around the sphere.
[SerializeField] private float _radius;
...
private void Start()
{
// Create transform matrices for our three example instances
var matrices = new float4x4[_instancesCount];
for (var i = 0; i < matrices.Length; i++)
{
matrices[i] = Matrix4x4.Translate(Random.onUnitSphere * _radius);
}
...
}
...

Here you can grab the full source code of the modified simple example: SimpleBRGExample.cs @GitHub
Now let’s move on to the more practical example.
4. Boids
4.1 Render Boids
As calculating boids movement is not the topic of this post, I used this boids repository by ThousandAnt. It uses the Job System + Burst. What is more, it provides boids examples made with GameObjects and Instancing, which comes quite handy to compare both variants with BRG. However, for me this boids solution turned out to be kinda fragile, as even little performance dips or interaction with the editor breaks the _centerFlock pointer, leaves it as (NaN, NaN, NaN) and boids stop working. So in the editor I was able to test only up to 2k objects and 1k in deep profiling. I was mostly writing my code while testing with 2 instances for easier debugging, so when I had found out about this issue, I was too lazy to find a new boids lib and redo BRG variant again. Anyway, it was enough to make a conclusion, so let’s go ahead.
As I was investigating other examples provided by Unity in parallel, the boids renderer is based on another code from Unity’s graphics repository. And this is great because we can see here different approaches of packing data for BRG.
A simple example uses PackedMatrix or float3x4 to represent data. And the boids example uses just a NativeArray<Vector4>. So don’t forget how data should be stored by columns as discussed in Part 1.
It is a very important point to know how sequentially your data should be packed, nevertheless, it is float, float4, float3x4, or any other type you decided to use.
You can check the full initial version of BatchRenderGroupBoidsRunner.cs @gist.github.com or let’s break it down right here.
My class extends Runner provided by boids repo and contains settings for boids simulation. We also need to declare the following private fields:
public unsafe class BatchRenderGroupBoidsRunner : Runner
{
[SerializeField] private Mesh _mesh;
[SerializeField] private Material _material;
private PinnedMatrixArray _matrices;
private NativeArray<float> _noiseOffsets;
private float3* _centerFlock;
private JobHandle _boidsHandle;
private BatchRendererGroup _batchRendererGroup;
private GraphicsBuffer _gpuPersistentInstanceData;
private NativeArray<Vector4> _dataBuffer;
private BatchID _batchID;
private BatchMaterialID _materialID;
private BatchMeshID _meshID;
private bool _initialized;
...
}
Then we have to init BRG, as well as boids in the Start method. The BRG init is similar to the one provided in the simple example, with a small difference. Here we use a single NativeArray<Vector4> _dataBuffer instead of separate arrays with _worldToObject and _objectToWorld matrices. The boids init is taken from examples provided in the boids repo.
To increase readability it is better to extract these 2 inits into separate methods.
private void Start()
{
InitBoids();
InitBatchRendererGroup();
}
private void InitBatchRendererGroup()
{
_batchRendererGroup = new BatchRendererGroup(OnPerformCulling, IntPtr.Zero);
var bounds = new Bounds(new Vector3(0, 0, 0), new Vector3(1048576.0f, 1048576.0f, 1048576.0f));
_batchRendererGroup.SetGlobalBounds(bounds);
if (_mesh)
{
_meshID = _batchRendererGroup.RegisterMesh(_mesh);
}
if (_material)
{
_materialID = _batchRendererGroup.RegisterMaterial(_material);
}
var objectToWorldID = Shader.PropertyToID("unity_ObjectToWorld");
var worldToObjectID = Shader.PropertyToID("unity_WorldToObject");
const int matrixSizeInFloats = 4;
const int packedMatrixSizeInFloats = 3;
const int matricesPerInstance = 2;
// float4x4.zero + per instance data = { 2 * float3x4 }
var bigDataBufferVector4Count = matrixSizeInFloats + Size * packedMatrixSizeInFloats * matricesPerInstance;
_dataBuffer = new NativeArray<Vector4>(bigDataBufferVector4Count, Allocator.Persistent);
var bigDataBufferFloatCount = bigDataBufferVector4Count * 4;
_gpuPersistentInstanceData = new GraphicsBuffer(GraphicsBuffer.Target.Raw, bigDataBufferFloatCount, 4);
// 64 bytes of zeroes, so loads from address 0 return zeroes. This is a BatchRendererGroup convention.
_dataBuffer[0] = Vector4.zero;
_dataBuffer[1] = Vector4.zero;
_dataBuffer[2] = Vector4.zero;
_dataBuffer[3] = Vector4.zero;
_gpuPersistentInstanceData.SetData(_dataBuffer);
var positionOffset = UnsafeUtility.SizeOf<Matrix4x4>();
var inverseGpuAddress = positionOffset + Size * UnsafeUtility.SizeOf<float3x4>();
var batchMetadata =
new NativeArra<MetadataValue>(2, Allocator.Temp, NativeArrayOptions.UninitializedMemory)
{
[0] = CreateMetadataValue(objectToWorldID, positionOffset, true),
[1] = CreateMetadataValue(worldToObjectID, inverseGpuAddress, true),
};
_batchID = _batchRendererGroup.AddBatch(batchMetadata, _gpuPersistentInstanceData.bufferHandle);
_initialized = true;
}
private void InitBoids()
{
_matrices = new PinnedMatrixArray(Size);
_noiseOffsets = new NativeArray<float>(Size, Allocator.Persistent);
for (var i = 0; i < Size; i++)
{
var currentTransform = transform;
var pos = currentTransform.position + Random.insideUnitSphere * Radius;
var rotation = Quaternion.Slerp(currentTransform.rotation, Random.rotation, 0.3f);
_noiseOffsets[i] = Random.value * 10f;
_matrices.Src[i] = Matrix4x4.TRS(pos, rotation, Vector3.one);
}
_centerFlock = (float3*) UnsafeUtility.Malloc(
UnsafeUtility.SizeOf<float3>(),
UnsafeUtility.AlignOf<float3>,
Allocator.Persistent);
UnsafeUtility.MemSet(_centerFlock, 0, UnsafeUtility.SizeO<float3>());
}
In Update we complete the previously scheduled job, update _dataBuffer and GraphicsBuffer, and schedule new jobs to simulate boids.
private void Update()
{
_boidsHandle.Complete();
transform.position = *_centerFlock;
UpdatePositions();
_gpuPersistentInstanceData.SetData(_dataBuffer);
...
}
private void UpdatePositions()
{
const int positionOffset = 4;
var itemCountOffset = 3 * Size; // 3xfloat4 per matrix times amount of instances
for (var i = 0; i < Size; i++)
{
{
_dataBuffer[positionOffset + i * 3 + 0] = new Vector4(_matrices.Src[i].m00, _matrices.Src[i].m10, _matrices.Src[i].m20, _matrices.Src[i].m01);
_dataBuffer[positionOffset + i * 3 + 1] = new Vector4(_matrices.Src[i].m11, _matrices.Src[i].m21, _matrices.Src[i].m02, _matrices.Src[i].m12);
_dataBuffer[positionOffset + i * 3 + 2] = new Vector4(_matrices.Src[i].m22, _matrices.Src[i].m03, _matrices.Src[i].m13, _matrices.Src[i].m23);
var inverse = Matrix4x4.Inverse(_matrices.Src[i]);
_dataBuffer[positionOffset + i * 3 + 0 + itemCountOffset] = new Vector4(inverse.m00, inverse.m10, inverse.m20, inverse.m01);
_dataBuffer[positionOffset + i * 3 + 1 + itemCountOffset] = new Vector4(inverse.m11, inverse.m21, inverse.m02, inverse.m12);
_dataBuffer[positionOffset + i * 3 + 2 + itemCountOffset] = new Vector4(inverse.m22, inverse.m03, inverse.m13, inverse.m23);
}
}
}
4.2 BRG vs GameObjects
Firstly, let’s compare BRG boids to GameObjects implementation, which is available in the ThousandAnt repo. This example is great as boids calculation is jobified using IJobParallelFor, as well as TransformAccessArray is used, which significantly improves performance of updating a bunch of transforms. I used 2000 instances for this test.
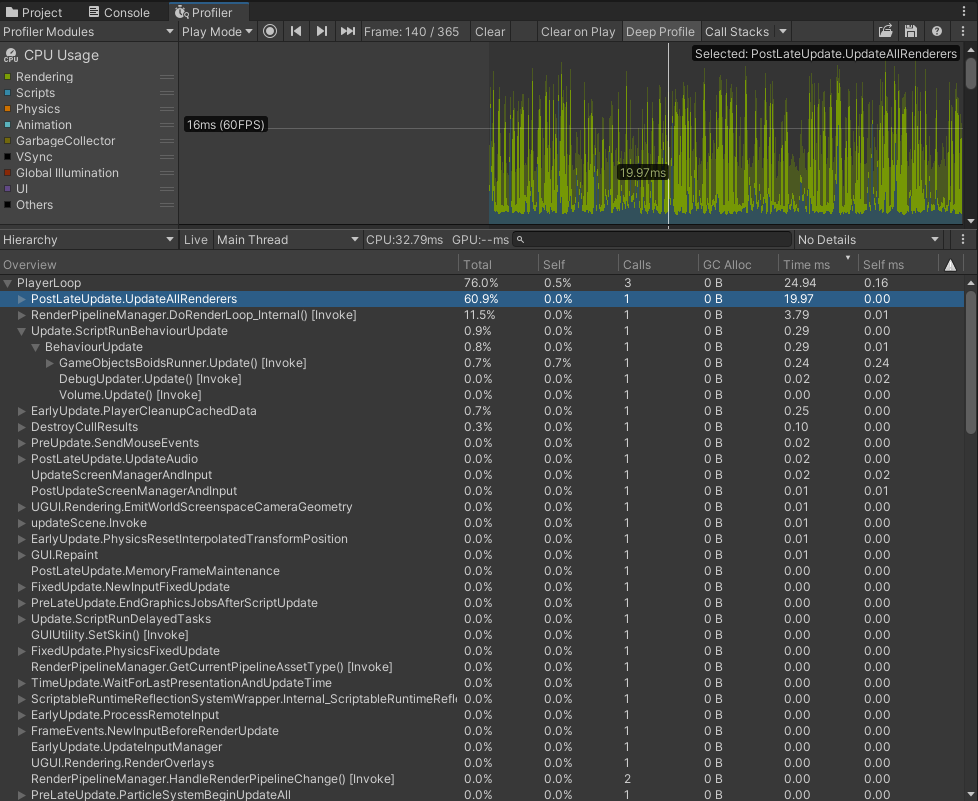
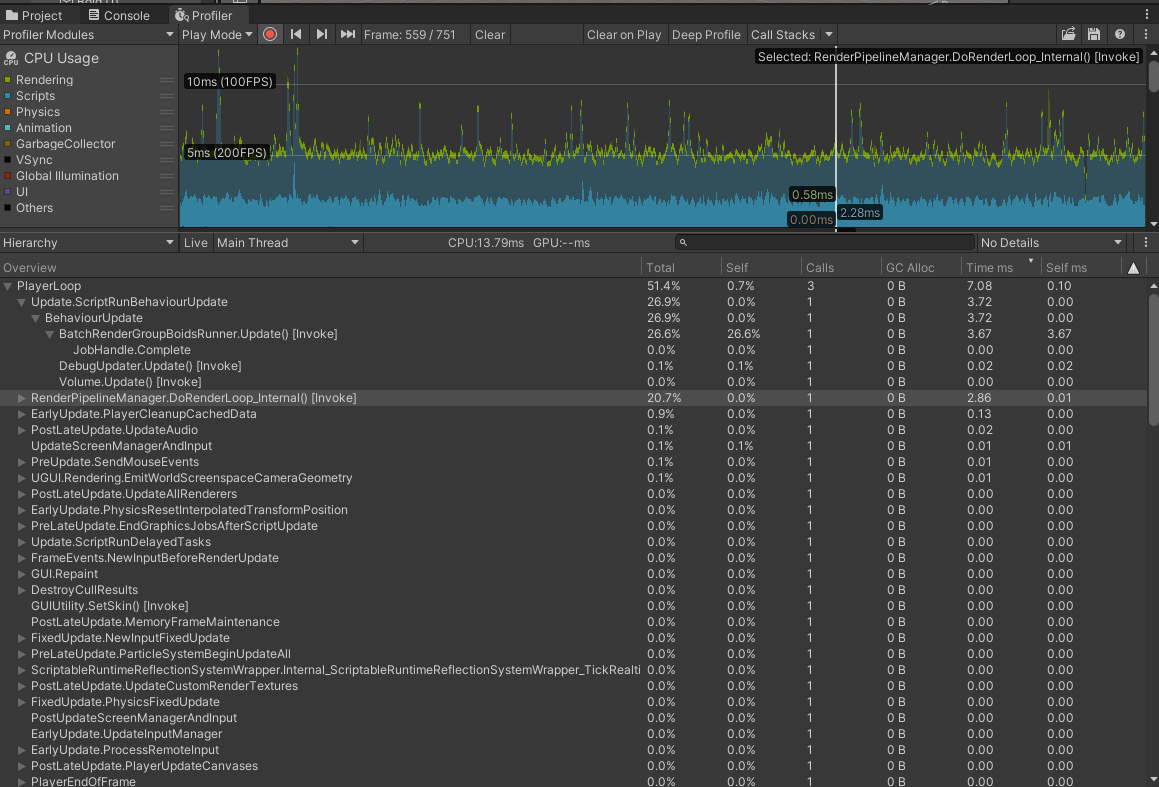
BRG here is the clear winner. Not only does it render faster, but it also doesn’t have the problem of a big amount of transforms that are recalculated every frame in PostLateUpdate.UpdateAllRenderers, which is jobified internally, but still slow when every transform is changing every frame, even though all game objects are created in the root of the scene, so they are processed in the most optimal way (I have mentioned this point in another blog post with awesome performance tips by engineers from Unity).
Rendering of GameObjects is also slower, while Update of all these transforms positions is lightning fast because TransformAccessArray and jobs are used here. Update() of BRG runner is a lot slower though: 3.67ms vs 0.24ms for GameObjects implementation. But we will get to it later running deep profiler.
4.3 BRG vs Instancing
Now let’s compare BRG to Instancing, provided by the boids lib author. Again I am using 2000 instances for this test.
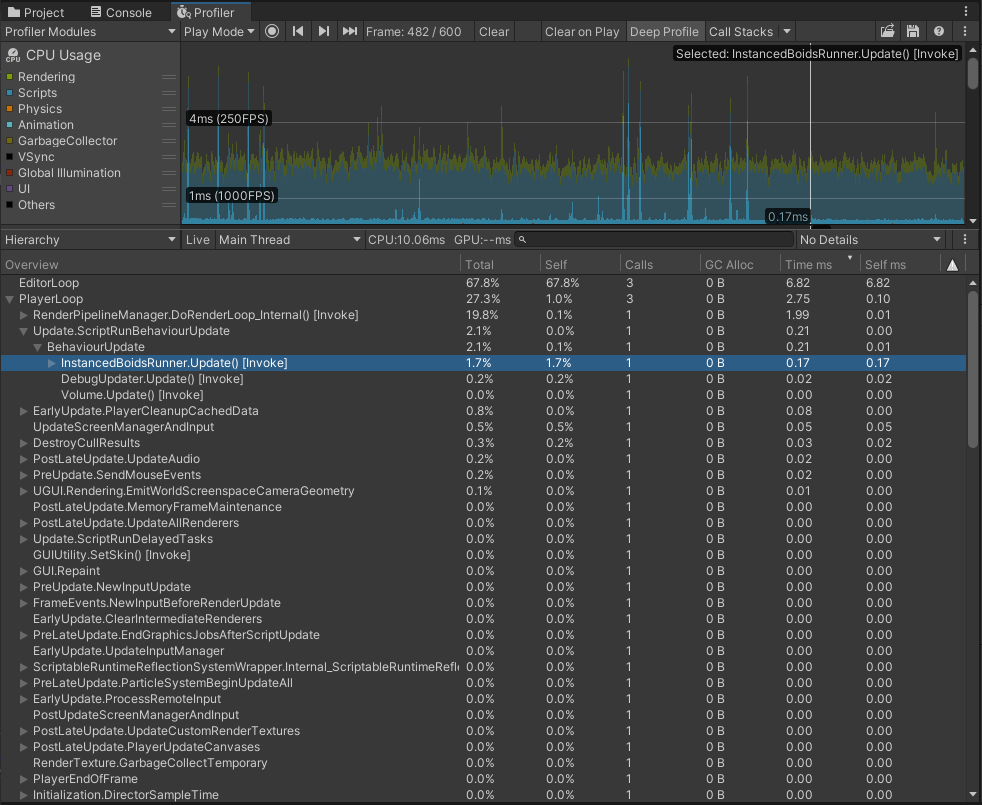
PlayerLoop with Instancing implementation takes around 2-3ms every frame. BRG with its ~7ms looks a lot slower, but why? Time to use deep profiling. Due to the issue with the boids algorithm, I am limiting the instance count to 1000, otherwise the algorithm is too unstable.
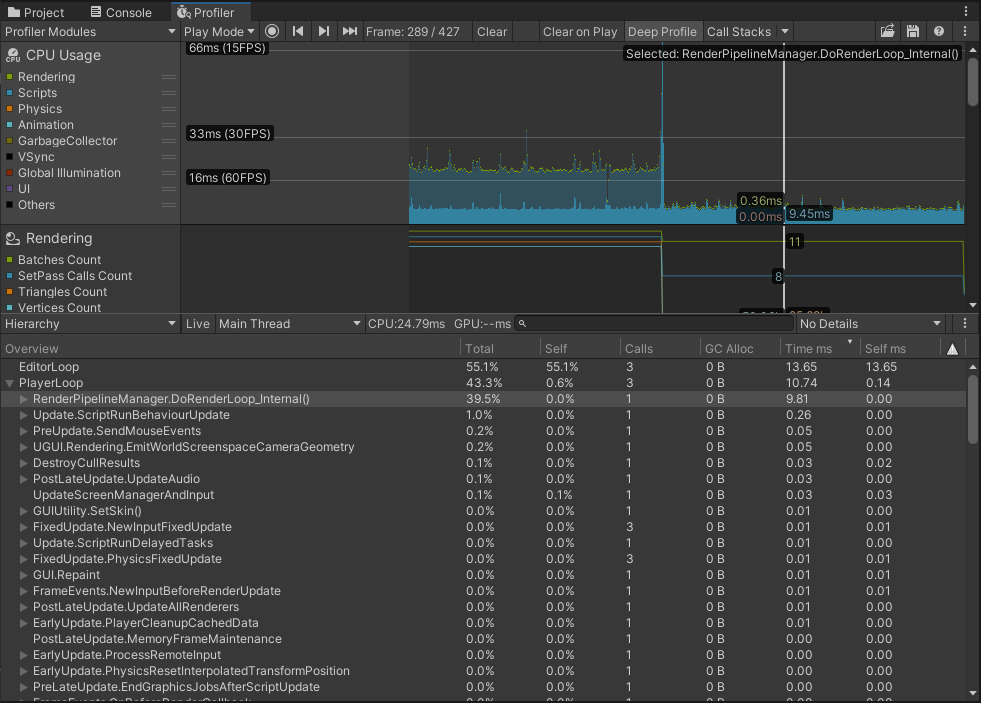
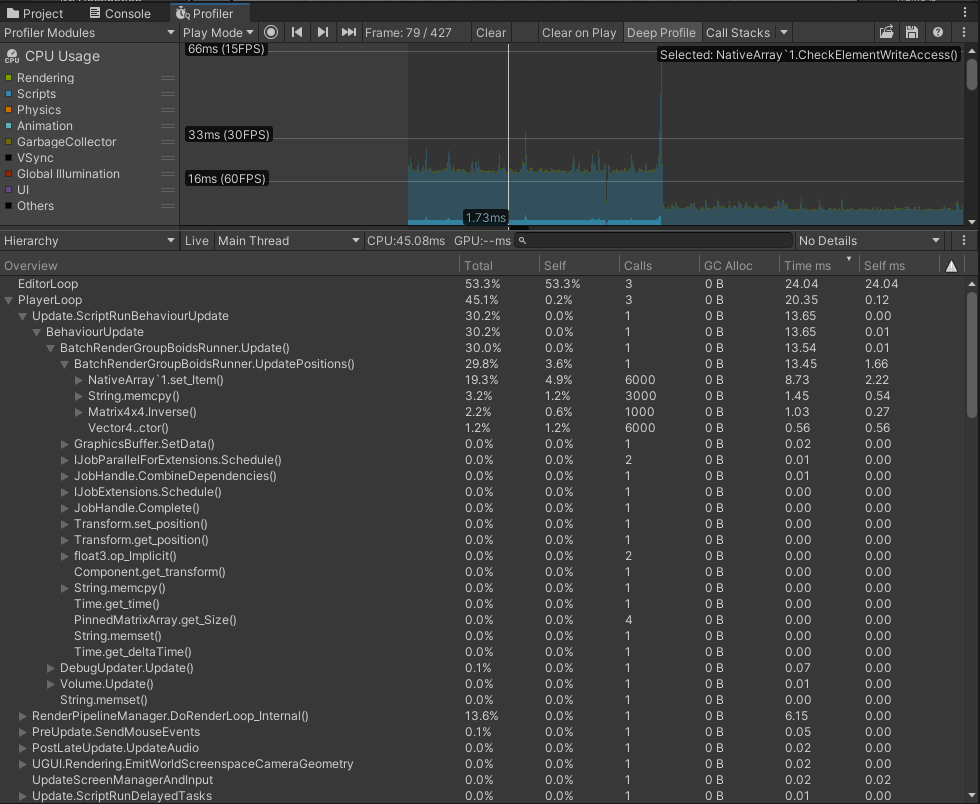
Rendering in DoRenderLoop_internal is on par for both variants, but Update() of BatchRendererGroupBoidsRunner is significantly slower.
No wonder looking at those numbers inside the UpdatePositions methods. The reason for this is the slow sequential update of _dataBuffer, calculating inverse for each matrix, and creating a ton of Vector4s. All of that is done in the main thread.
It can be optimized by moving update to the job system. To do this we need to remove completely Update methods from BatchRendererGroupBoidsRunner.
And create a new job that copies data from matrices to _dataBuffer:
[BurstCompile]
public unsafe struct CopyMatricesJob : IJobParallelFor
{
public int Size;
[ReadOnly] [NativeDisableUnsafePtrRestriction]
public float4x4* Source;
[WriteOnly] [NativeDisableParallelForRestriction]
public NativeArray<Vector4> DataBuffer;
private const int PositionOffset = 4;
public void Execute(int index)
{
DataBuffer[PositionOffset + index * 3 + 0] = new Vector4(Source[index].c0.x, Source[index].c0.y, Source[index].c0.z, Source[index].c1.x);
DataBuffer[PositionOffset + index * 3 + 1] = new Vector4(Source[index].c1.y, Source[index].c1.z, Source[index].c2.x, Source[index].c2.y);
DataBuffer[PositionOffset + index * 3 + 2] = new Vector4(Source[index].c2.z, Source[index].c3.x, Source[index].c3.y, Source[index].c3.z);
var offset = Size * 3;
var inverse = Matrix4x4.Inverse(Source[index]);
DataBuffer[PositionOffset + index * 3 + 0 + offset] = new Vector4(inverse.m00, inverse.m10, inverse.m20, inverse.m01);
DataBuffer[PositionOffset + index * 3 + 1 + offset] = new Vector4(inverse.m11, inverse.m21, inverse.m02, inverse.m12);
DataBuffer[PositionOffset + index * 3 + 2 + offset] = new Vector4(inverse.m22, inverse.m03, inverse.m13, inverse.m23);
}
}
Make sure to add [NativeDisableParallelForRestriction] attribute, because the job safety system will prevent you from writing to arbitrary indices from within the job’s kernel, but we need to update 3 neighboring entries, as well as an inverse matrix. This attribute allows disabling this check by basically saying that you guarantee there will be no race condition.
And of course, we need to schedule the new job and update GraphicsBuffer when the data is ready:
private void Update()
{
_boidsHandle.Complete();
transform.position = *_centerFlock;
_gpuPersistentInstanceData.SetData(_dataBuffer);
var avgCenterJob = new BoidsPointerOnly.AverageCenterJob
{
Matrices = _matrices.SrcPtr,
Center = _centerFlock,
Size = _matrices.Size
}.Schedule();
var boidsJob = new BoidsPointerOnly.BatchedBoidJob
{
Weights = Weights,
Goal = Destination.position,
NoiseOffsets = _noiseOffsets,
Time = Time.time,
DeltaTime = Time.deltaTime,
MaxDist = SeparationDistance,
Speed = MaxSpeed,
RotationSpeed = RotationSpeed,
Size = _matrices.Size,
Src = _matrices.SrcPtr,
Dst = _matrices.DstPtr,
}.Schedule(_matrices.Size, 32);
var copyJob = new CopyMatricesJob
{
DataBuffer = _dataBuffer,
Size = _matrices.Size,
Source = _matrices.SrcPtr
}.Schedule(_matrices.Size, 32);
var combinedJob = JobHandle.CombineDependencies(boidsJob, avgCenterJob, copyJob);
_boidsHandle = new BoidsPointerOnly.CopyMatrixJob
{
Dst = _matrices.SrcPtr,
Src = _matrices.DstPtr
}.Schedule(_matrices.Size, 32, combinedJob);
}
Let’s profile the optimized version to check if the optimization was useful.
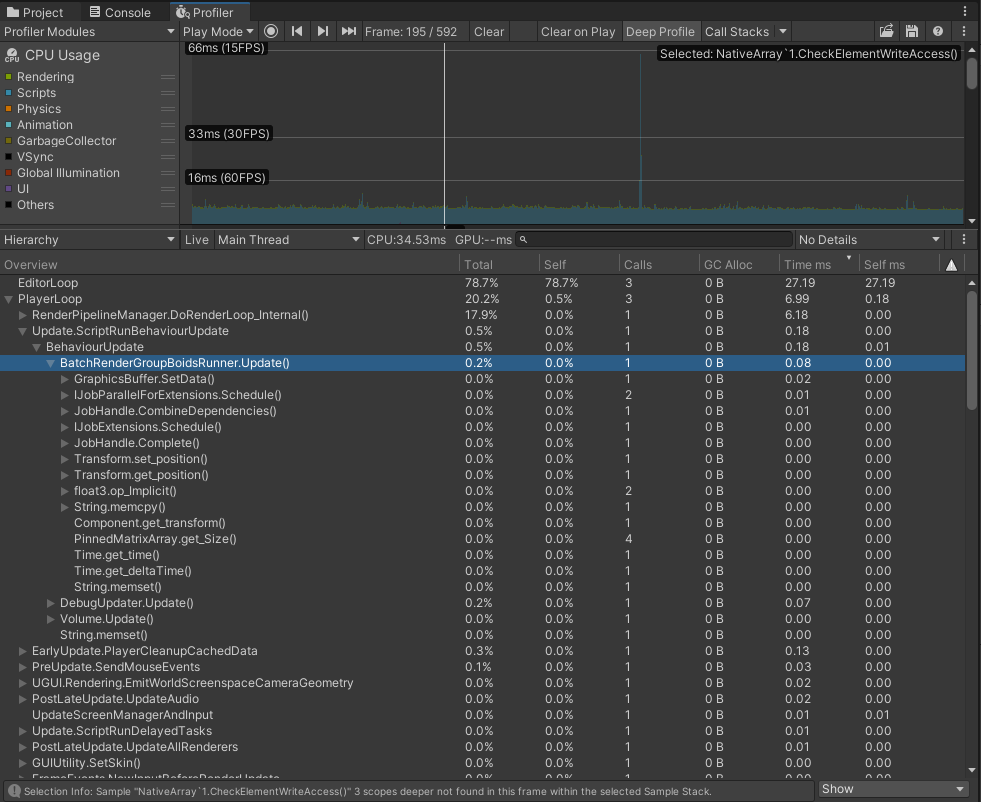
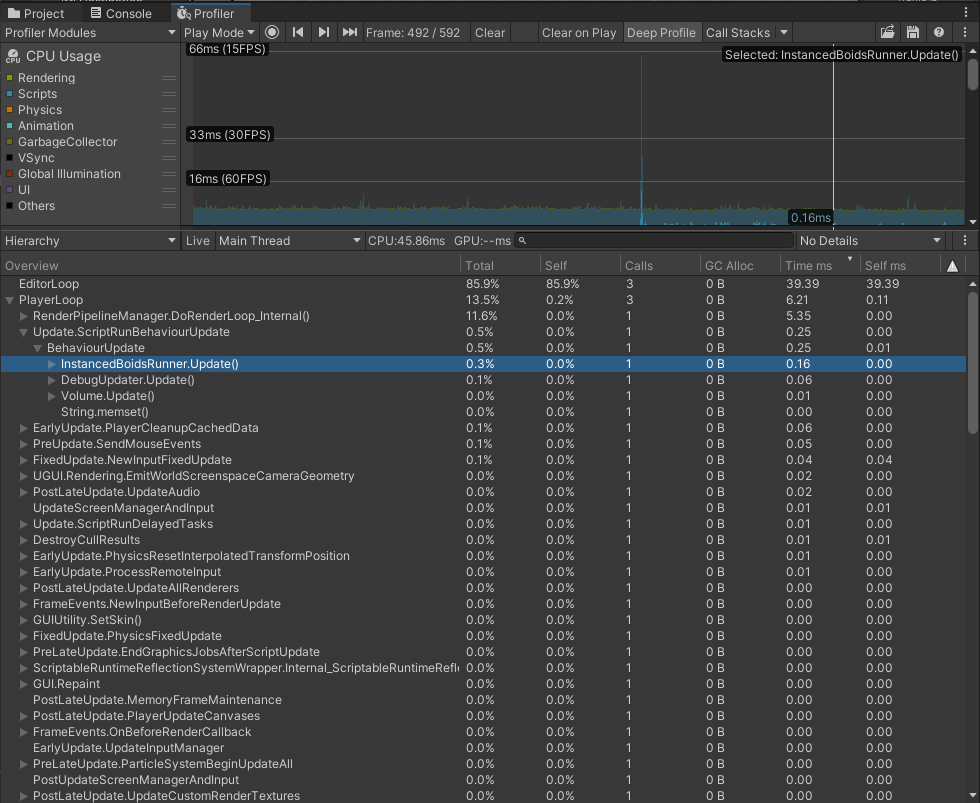
Well, it was a good optimization attempt indeed.
After Update is optimized by moving _dataBuffer update to a parallel job, we got similar performance here. On average Instanced variant runs just a little bit faster, but in deep profiling of 1k objects, we can see that Graphics.DrawMeshInstanced() takes more time than the whole Update of the BRG variant. However, BRG loses a bit in DoRenderLoop_internal. The final version is available here: Boids BRG @Github. And of course, you can get the whole project on GitHub too: https://github.com/AlexMerzlikin/Unity-BatchRendererGroup-Boids.
Conclusion
The example with a single mesh and a single material shows great performance on par with instancing. I would like to compare performance on a mobile device too, as well as try to use BRG for a more complex scene with different meshes and materials, and use Burst and Job System to implement culling and draw command output, but that’s gonna be another blog post, as this one is kinda big already.
And it definitely took so much time to prepare. So while I am working on the next post you can give my telegram channel a follow where I post stuff I find interesting on a daily basis.
Leave a Reply